- This topic has 12 replies, 5 voices, and was last updated April 29, 2022 at 5:21 pm by .
-
Topic
-
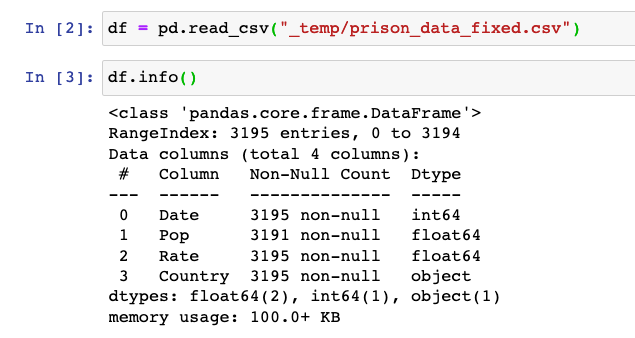
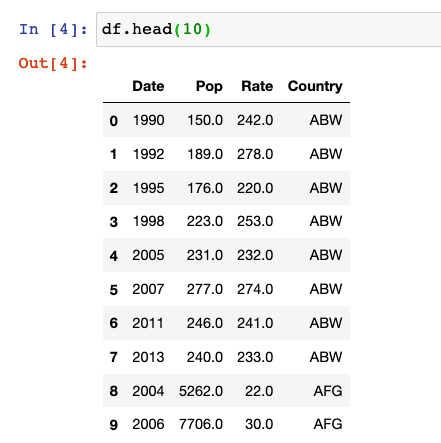
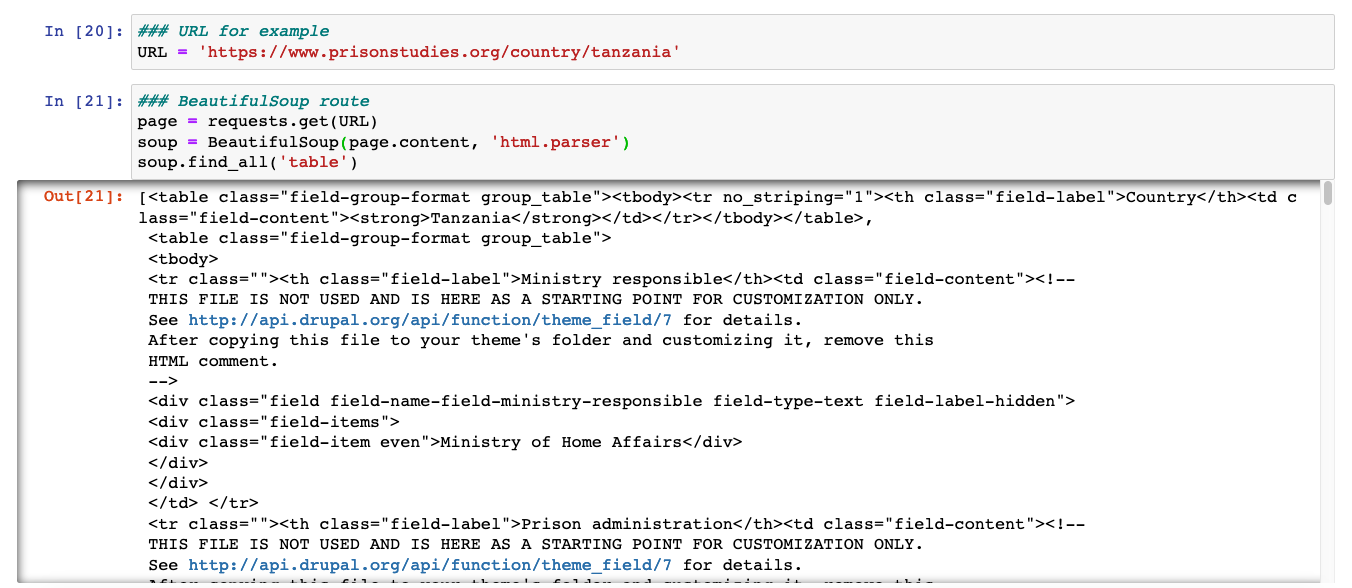
Over the summer I have been practicing web scraping with Python. If anyone has research that could benefit from batch downloading from ugly or tricky websites, feel free to post here! I would also be happy to give some tips if you want to do this yourself.
For example, I downloaded all prison rate data from https://www.prisonstudies.org/world-prison-brief-data. The data is available for free, but you will notice that it is annoying to get a lot of data. You have to click on every country and then find the table(s) that have prison rate data.
A little code and voila! Attached to this post is a csv of all world prison rate data from World Prison Brief. Below is all of the world data binned and plotted over time.
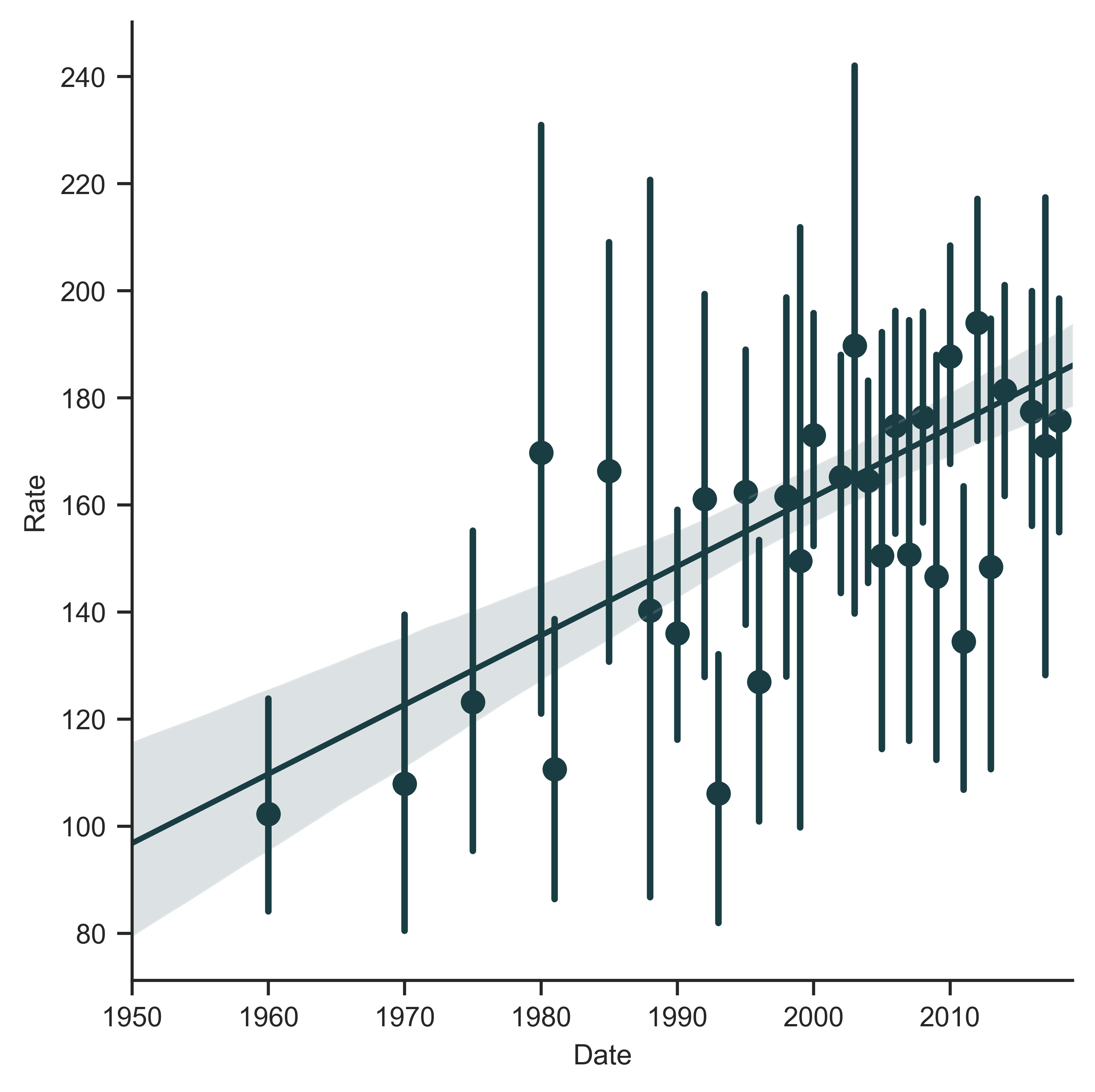
The timing of my curiosity in downloading prison rate data and rising incarceration rates is not accidental. Hopefully 2020 is the year more people recognize that BLACK LIVES MATTER.
- You must be logged in to reply to this topic.