- This topic has 11 replies, 4 voices, and was last updated November 9, 2021 at 8:30 pm by .
-
Topic
-
A modern corporation is likely to possess at least one trademark, as a trademark is the type of intellectual property one uses to register the ownership of images, designs or symbols. These images, designs or symbols, like the Nike swoosh or the BMW quartered circle, are central to protecting a company’s brand identity. Culturally, when we think of a brand identity, we tend not to think of intellectual property law; only the most detail-oriented lawyer would know the serial numbers of Apple from memory. Yet ownership of a trademark is always below the surface of our cultural relationships with brands. Trademark ownership enables, when needed, for a company like Apple to act against any party it believes is creating a design that looks a lot like the silhouette of an apple with a bite in it, or against anyone that is unauthorized to reproduce Apple’s logos. Ownership also forces someone to pay for the legal usage of someone else’s trademark — excluding the terms of “fair use”.
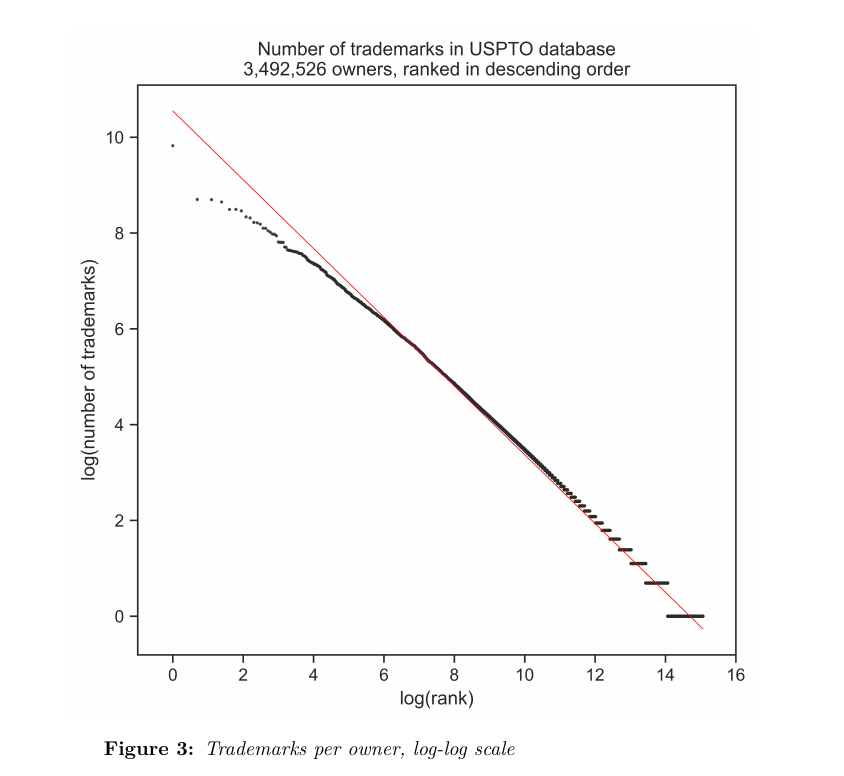
If a modern corporation builds its brand with trademarks, how many trademarks does a company typically own? The brand power of some corporations are influential culturally and successful financially. Do these corporations own more trademarks than others? For instance, how many trademarks do companies like Nike or Disney own?
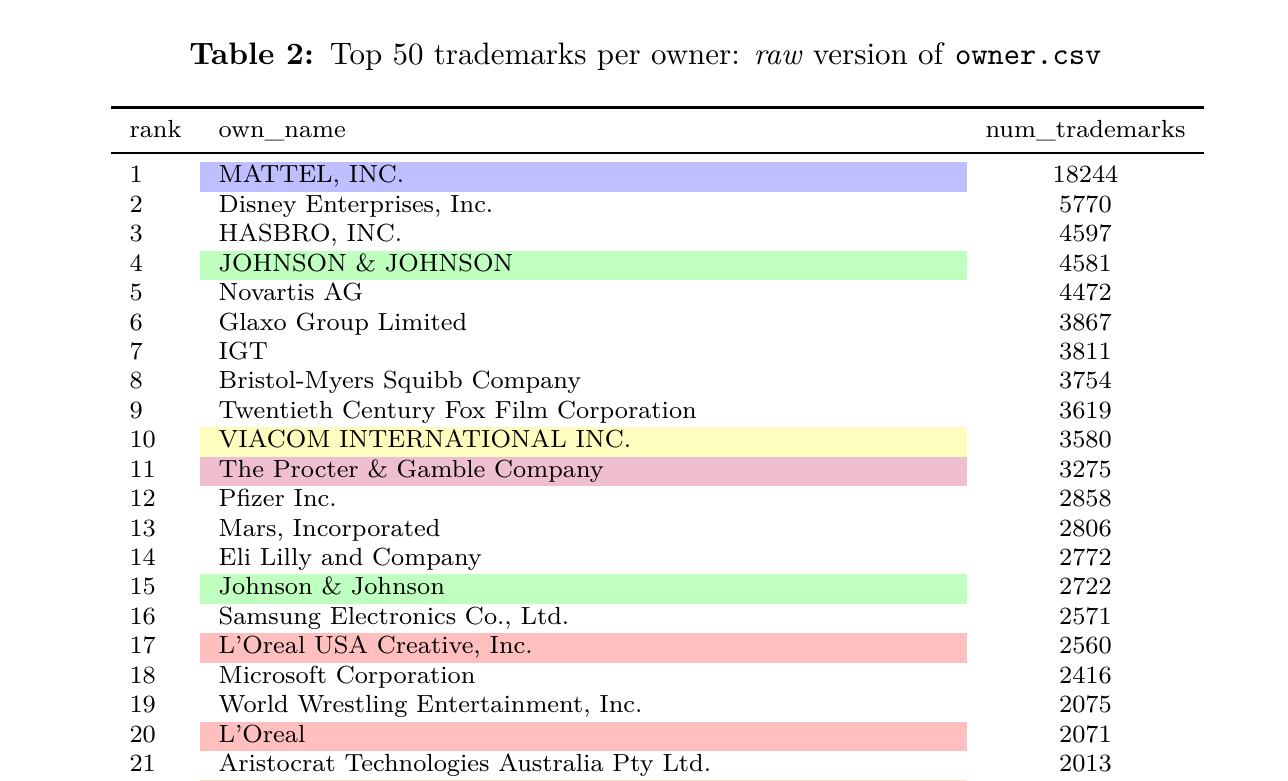
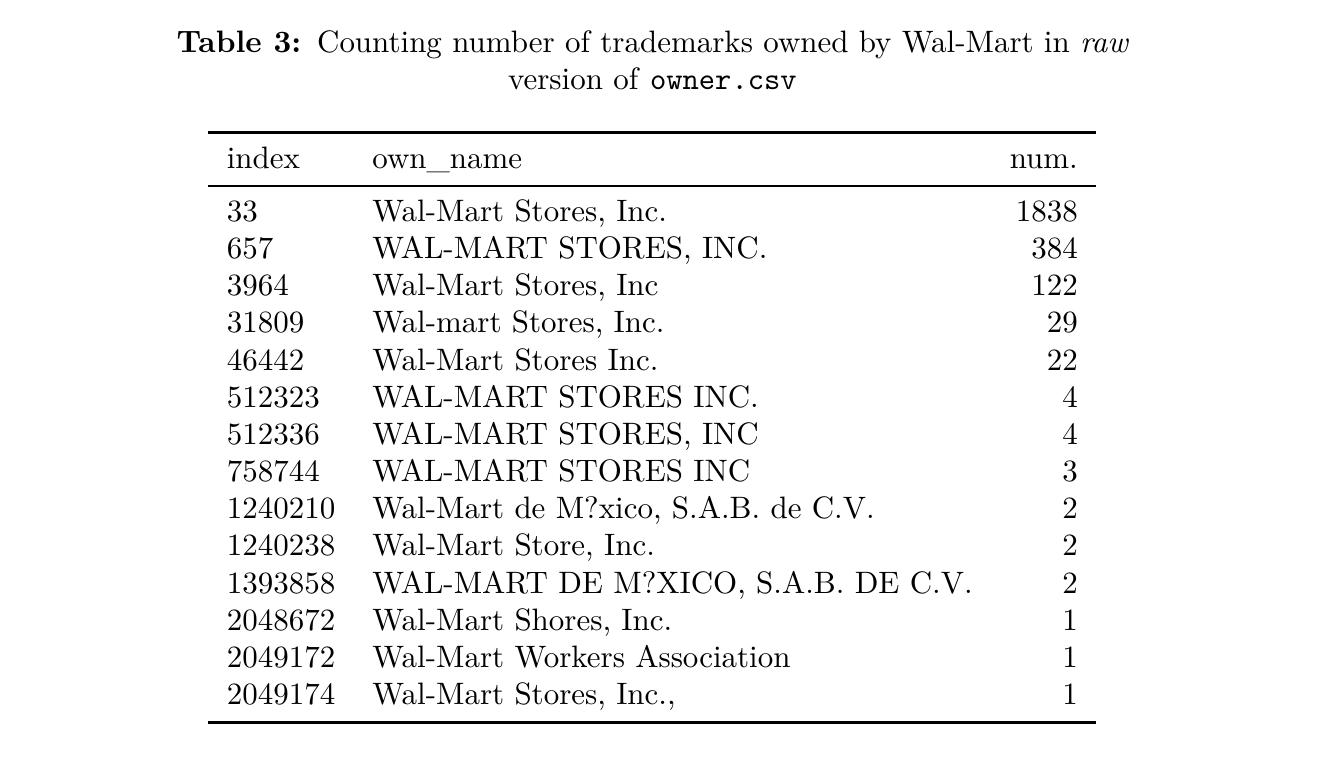
Questions like these can be answered with statistical software, but doing so requires that the data are first cleaned. A dataset of trademarks is essentially a number of case files stacked on top of each other. The information of one trademark occupies one row in the dataset. The information in that row can be accurate, but alternatively it could have typos or misspellings. While errors like typos or misspellings are at most minor annoyances to a human reader, they severely hamper the production of quality aggregate data with software. Basic grouping functions in software such as R and Python will only match names strings that are exactly the same.
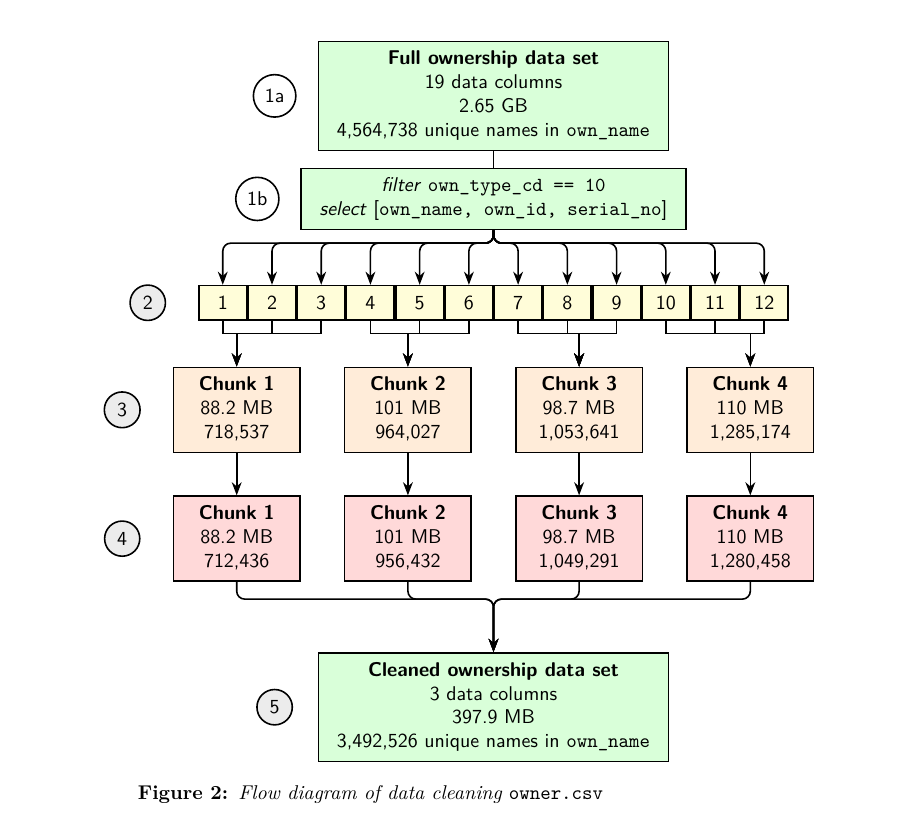
This document describes the steps I took to clean the ownership data of the United States Patent and Trademark Office (USPTO). The goal of this cleaning was to increase the likelihood that when trademarks were counted per owner (with Python, R, etc.), owners were not separated according to small differences in strings, such as case or typos in names.
Once cleaned, the ownership data can support critical research in intellectual property. For now, the version 1 of the cleaned and grouped USPTO ownership data is available here. Questions or suggestions are welcome, as the goal is to develop a dataset that helps researchers find trends or interesting things in trademark data.
- You must be logged in to reply to this topic.